华中科技大学自然语言处理工具包(HUST-NLP)是华中科技大学认知计算与智能信息处理实验室(CCIIP)研发的一款轻量级的自然语言处理(NLP)处理套件,其具有统一的数据预处理组件,并提供了多种高级模块,如Transformer、CRF等;在序列标注、文本分类等NLP子任务上,HUST-NLP还封装了各种模型可供直接调用。在兼顾易用性的同时,HUST-NLP在中文分词、命名实体识别、词性标注、和文本分类等多个任务中都能够取得较好的效果。如果你需要快速地部署完成一个NLP任务,或是高效地构建对比模型进行科研,HUST-NLP可能是你很好的选择。
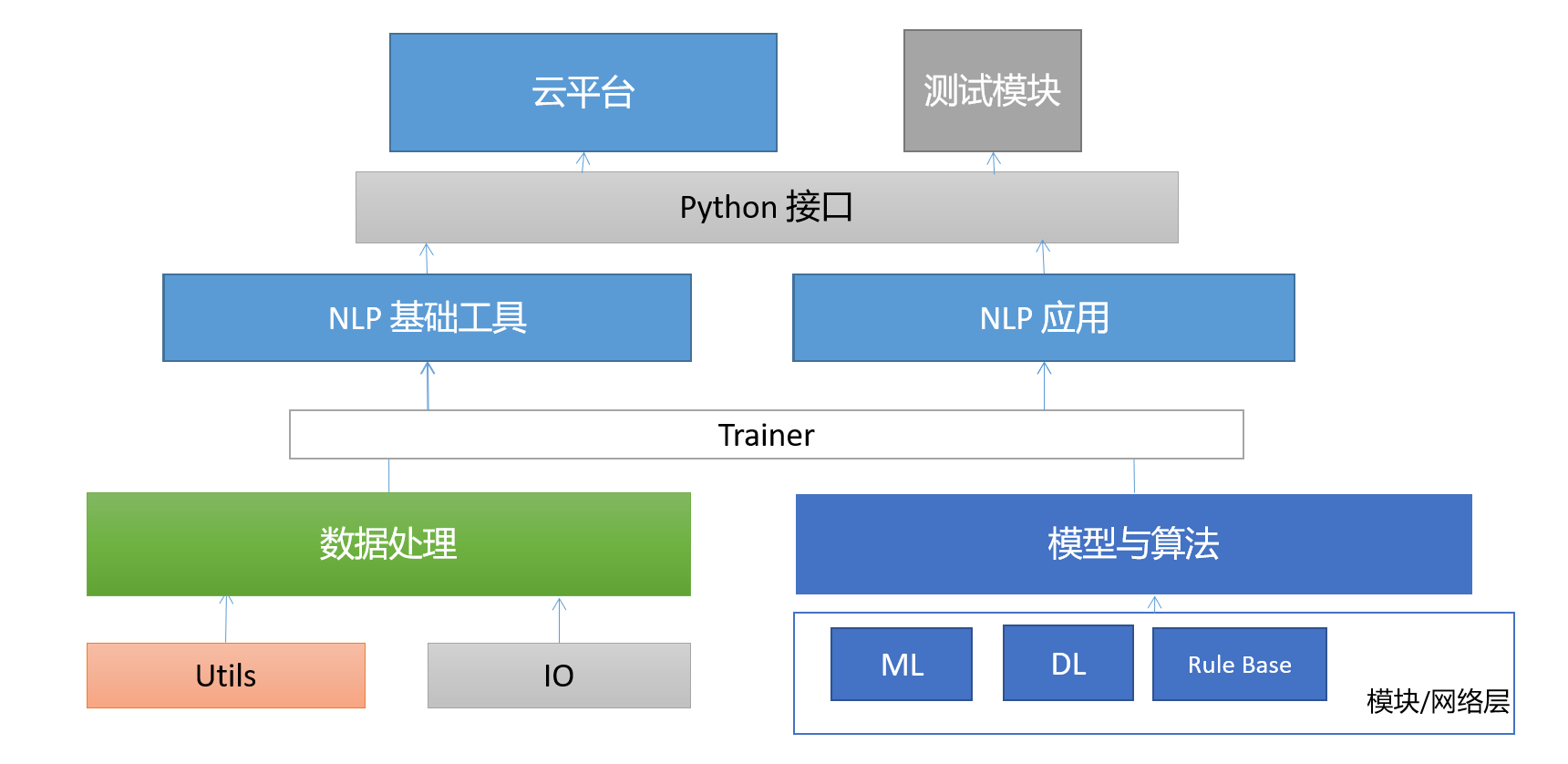
HUST-NLP架构
平台模块功能
平台各模块功能简介,包括中文分词、词性标注、命名实体识别、依存句法分析、句子分类和主谓宾分析等等。下面举例介绍HUST-NLP的功能:
中文分词
中文分词(Chinese Word Segmentation, CWS)是指将连续的汉字序列切分成词语序列。由于汉语中没有像英文中那样的词与词之间的天然分界符,而词又是表达语义的基本单位,因此中文分词就成为了下游NLP任务的基础。
分词模块在人民日报数据集上的性能如下:
|
数据集 |
人民日报 |
|
中文分词 |
F1(%) |
|
HUST-NLP (HUST) |
97.77 |
|
PyLTP (HIT) |
97.05 |
分词模块在自标注数据集(Dataset-200)上的性能如下:
|
Dataset-200 |
百科 |
知道 |
知乎 |
微博 |
|
中文分词 |
F1(%) |
F1(%) |
F1(%) |
F1(%) |
|
HUST-NLP (HUST) |
98.64 |
95.03 |
97.42 |
93.93 |
|
PyLTP (HIT) |
90.42 |
87.31 |
94.81 |
85.16 |
|
fastHan (FDU) |
85.55 |
84.08 |
91.16 |
84.81 |
|
Fool |
89.64 |
83.78 |
92.81 |
82.86 |
|
PKUSeg (PKU) |
88.6 |
84.52 |
93.00 |
77.61 |
|
JieBa |
81.1 |
78.67 |
87.02 |
78.04 |
|
THULAC (THU) |
87.26 |
80.03 |
81.85 |
77.71 |
|
HanLP |
83.04 |
81.47 |
86.63 |
83.15 |
|
SnowNLP |
78.13 |
76.72 |
87.14 |
64.77 |
|
PyNLPIR (CAS) |
88.09 |
82.56 |
91.91 |
80.87 |
|
Stanza (Stanford) |
75.74 |
69.09 |
77.72 |
67.98 |
词性标注
词性标注(Part-Of-Speech tagging, POS),是指是对连续的词语序列根据上下文内容进行词性的标注(如动词、名词、形容词等)。词性标注是很多NLP任务的预处理步骤,经过词性标注后的文本会给其它任务,如句法分析等,带来很大的便利性。
词性标注模块在人民日报数据集上的性能如下:
|
数据集 |
人民日报 |
|
词性标注 |
ACC(%) |
|
HUST-NLP (HUST) |
98.52 |
|
PyLTP (HIT) |
98.85 |
词性标注模块在自标注数据集(Dataset-200)上的性能如下:
|
Dataset-200 |
百科 |
知道 |
知乎 |
微博 |
|
词性标注 |
ACC(%) |
ACC(%) |
ACC(%) |
ACC(%) |
|
HUST-NLP (HUST) |
95.78% |
93.36% |
93.19% |
94.35% |
|
PyLTP (HIT) |
97.33% |
96.87% |
97.11% |
97.30% |
命名实体识别
命名实体识别(Named Entity Recognition, NER)是指识别中文文本中具有特定意义的实体指代的边界和类型,主要包括人名、地名、专有名词等。它是后续很多NLP任务(如依存句法分析、语义分析等)的基础,在自然语言处理领域占据重要地位。下图是HUST-NLP对句子“国务院总理李克强调研上海外高桥时提出,支持上海积极探索新机制。”的命名实体识别结果。
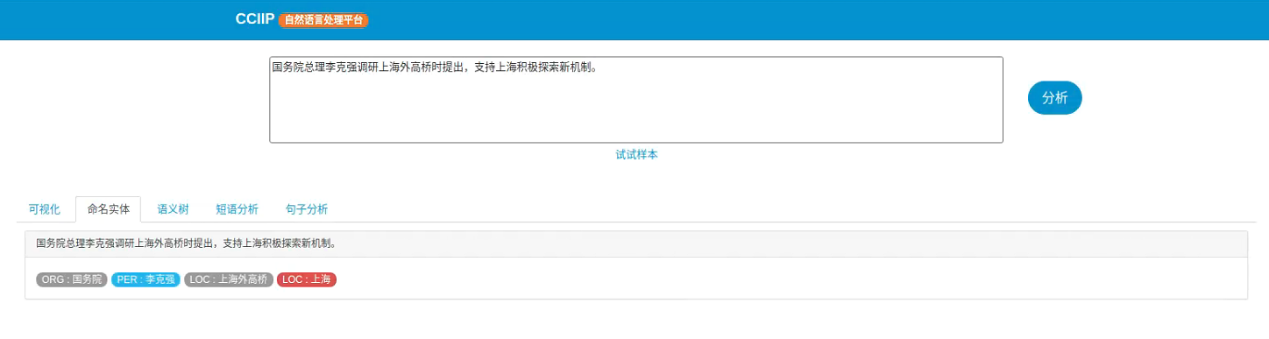
命名实体识别结果
命名实体识别模块在人民日报数据集上的性能如下:
|
数据集 |
人民日报 |
|
命名实体识别 |
F1(%) |
|
HUST-NLP (HUST) |
94.46 |
|
PyLTP (HIT) |
92.68 |
命名实体识别模块在自标注数据集(Dataset-200)上的性能如下:
|
Dataset-200 |
百科 |
知道 |
知乎 |
微博 |
|
命名实体识别 |
F1(%) |
F1(%) |
F1(%) |
F1(%) |
|
HUST-NLP (HUST) |
76.75% |
73.68% |
79.82% |
78.42% |
|
PyLTP (HIT) |
50.17% |
59.35% |
43.87% |
39.25% |
依存句法分析
依存句法分析(Syntactic Dependency Parsing)是通过分析句子内各语言成分之间的依存关系来解释其句法结构。依存句法分析能够帮助理解句子的结构和语义,对后续的语义分析、主谓宾分析等NLP任务都具有重要作用。下图是HUST-NLP对句子“国务院总理李克强调研上海外高桥时提出,支持上海积极探索新机制。”的依存句法分析结果。
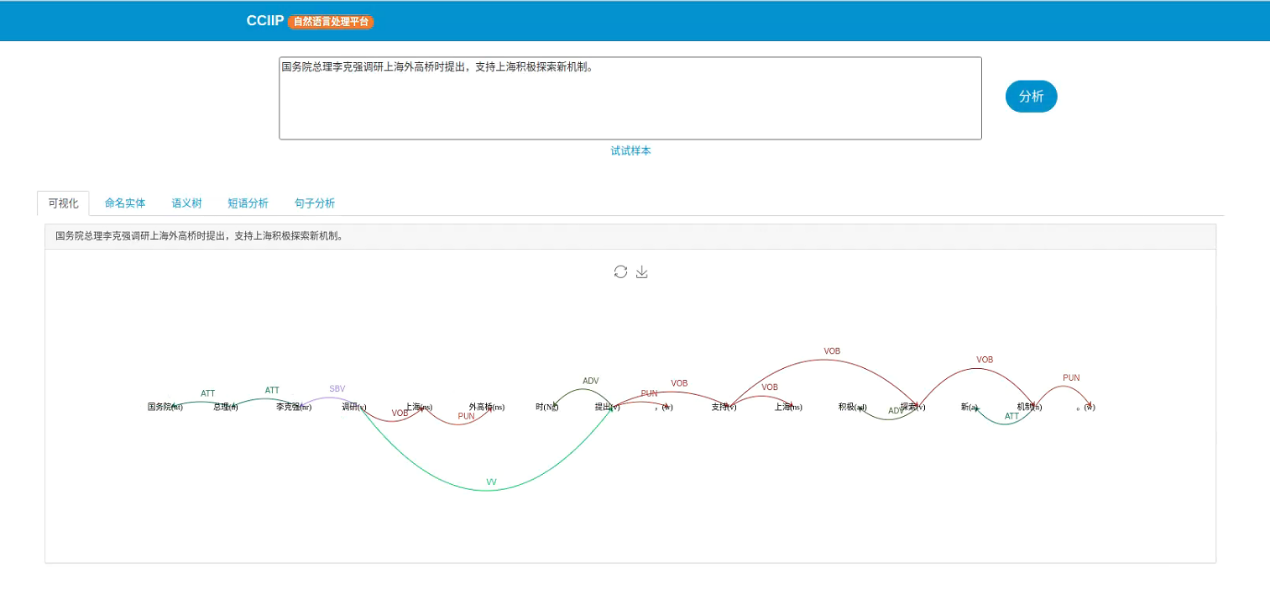
依存句法分析结果
语义依存分析
语义依存分析(Semantic Dependency Parsing)是对句子各个语言单位之间的关联进行分析,其结果一般通过语义树来展现。通过语义依存分析,能够在不受词汇本身和表层句法结构限制的情况下对句子的语义进行深入分析,对于让机器理解自然语言具有重要意义。下图是hustnlp对例句进行语义依存分析后,所生成的语义树的结果。
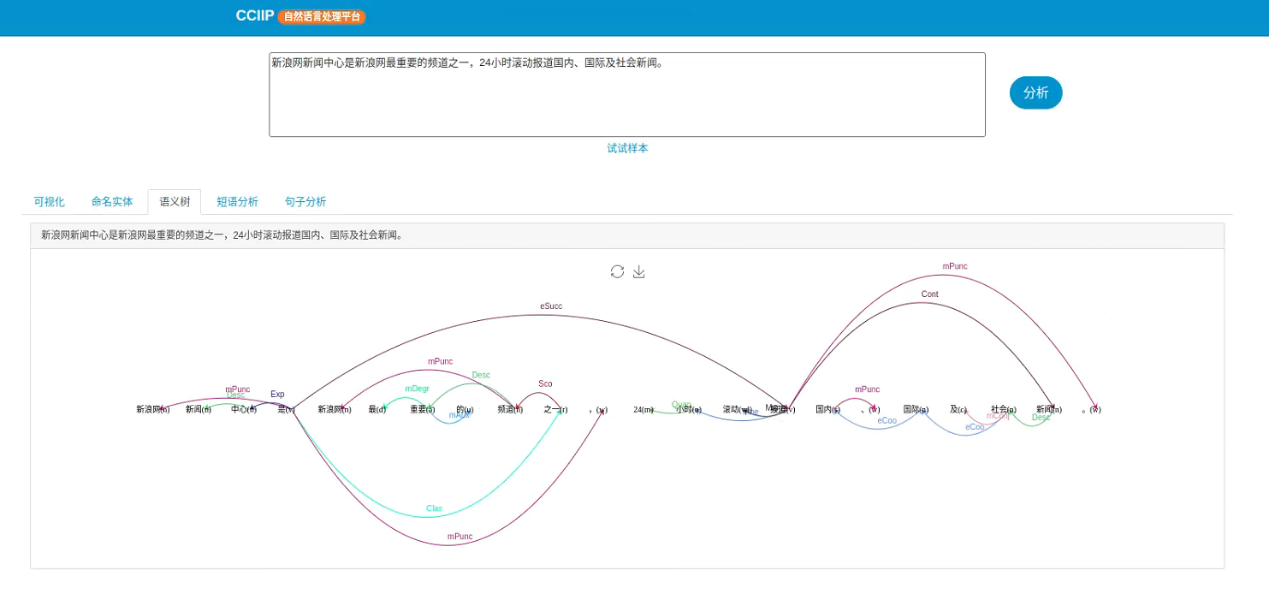
语义依存分析结果
短语分析
短语分析,判断句子中里面的状语成分,如时间状语,地点状语等 。 例句:我和李明在北京相遇。提取地点状语:“在北京。
句子分析
句子分析可分为以下几个部分:肯定/否定句判别,特指问句分类,句子分类,主谓宾标注。 肯定/否定句判别:判断一个句子表达的是“肯定”还是“否定”的含义。 特指问句分类:对特指问句进行提问类型的细化分类。 句子分类:对每个句子进行类型上的区分,如陈述句、是非问句、正反问句、感叹句、特指问句等 主谓宾标注:对每个句子的句法结构进行解析,将其主谓宾定状补的结构表示出来。
|
|
百科 |
知道 |
||||
|
|
Precision(%) |
Recall(%) |
F1 |
Precision(%) |
Recall(%) |
F1 |
|
肯定/否定判别 |
0.9948 |
1.0000 |
0.9974 |
0.9845 |
0.9948 |
0.9896 |
|
特指疑问句 |
0.0000 |
0.0000 |
0.0000 |
0.6196 |
0.5816 |
0.6000 |
|
句子分类 |
1.0000 |
1.0000 |
1.0000 |
0.8250 |
0.8250 |
0.8250 |
|
主谓宾标注 |
0.6532 |
0.6726 |
0.6628 |
0.5105 |
0.4449 |
0.4754 |
|
|
知乎 |
微博 |
||||
|
|
Precision(%) |
Recall(%) |
F1 |
Precision(%) |
Recall(%) |
F1 |
|
肯定/否定判别 |
0.9848 |
1.0000 |
0.9924 |
0.9897 |
0.9897 |
0.9897 |
|
特指疑问句 |
0.7546 |
0.7365 |
0.7455 |
0.6667 |
0.7273 |
0.6957 |
|
句子分类 |
0.9650 |
0.9650 |
0.9650 |
0.8900 |
0.8900 |
0.8900 |
|
主谓宾标注 |
0.6375 |
0.5767 |
0.6056 |
0.5516 |
0.4843 |
0.5158 |
文本纠错
文本纠错(Text Corretion)是指根据上下文内容对中文文本进行错字纠错,主要的错误类型有拼写错误、叠字错误和标点符号错误等。

文本纠错(Text Corretion)
HUST-NLP文本纠错模块性能如下:
数据集 | 模型 | 检错 | 纠错 | ||||
P | R | F1 | P | R | F1 | ||
自标注数据集 | HUST-NLP | 0.9723 | 0.8833 | 0.928 | 0.9469 | 0.8412 | 0.8909 |
Faspell(EMNLP 2019) | 0.9623 | 0.8305 | 0.8912 | 0.9218 | 0.7843 | 0.8475 | |
公开数据集SIGHAN15 | HUST-NLP | 0.8558 | 0.8319 | 0.8436 | 0.5583 | 0.5807 | 0.5682 |
Faspell(EMNLP 2019) | 0.8778 | 0.7808 | 0.8265 | 0.6619 | 0.5934 | 0.6258 | |
注:其中检错基于sentence-level,纠错采用的评估脚本基于m2score。
情感分析
情感分析(Sentiment Analysis)是通过分析句子中的情感语义,对文本中的观点进行极性分类,同时给出对应的置信度。
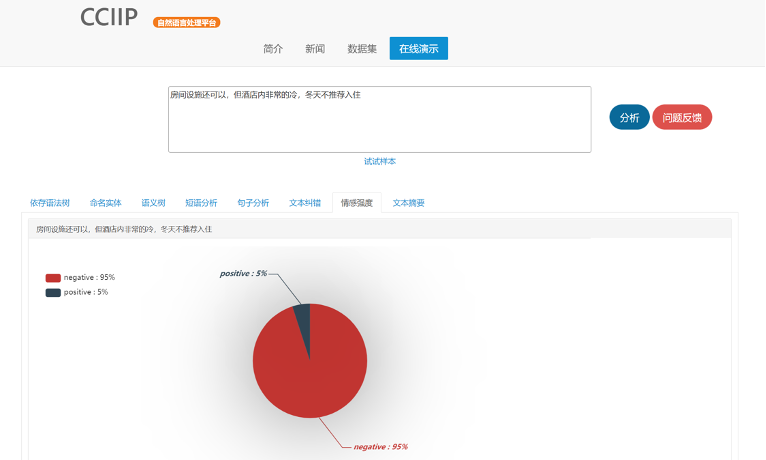
情感分析
HUST-NLP情感分析模块性能如下:
|
数据集 |
模型 |
ACC(%) |
|
ChnSentiCorp |
HUST-NLP |
95.80% |
|
SKEP |
96.50% |
SKEP:Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis,ACL 2020
自动文本摘要
自动文本摘要(Automatic Text Summarization)利用自然语言生成技术为新闻文本生成合适的标题。

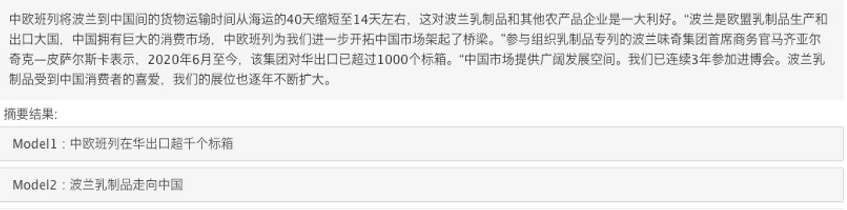
自动文本摘要
HUST-NLP自动文本摘要模块性能如下:
|
|
rouge-1 |
rouge-2 |
rouge-l |
|
模型一 |
0.3088 |
0.1932 |
0.2899 |
|
模型二 |
0.3352 |
0.2086 |
0.3133 |
注:训练数据集为LCSTS-2的PART-I前10万条数据,测试数据集为PART-III
模块性能指标
平台对各个模块的指标都进行了定义,包括中文分词、词性标注、命名实体识别、依存句法分析、句子分类和主谓宾分析等等。举例介绍如下:
中文分词
在HUST-NLP中,我们采用基于字的算法,将中文分词任务视作序列标注问题。算法会对输入序列的每个字预测一个标签,该标签对应于词语边界的标识。 目前,HUST-NLP的中文分词模块在人民日报的测试集上取得了如下的结果:
| P | R | F1 | |
|---|---|---|---|
| LTP | 96.80% | 97.30% | 97.05% |
| HUST-NLP | 97.73% | 97.80% | 97.77% |
命名实体识别
在处理命名实体识别任务时,HUST-NLP采取的方法与中文分词类似,都是以汉字为基本单位,将其视作一个序列标注问题。在NER任务中,HUST-NLP会为每个汉字预测一个表示其命名实体边界的标签。 目前,在人民日报数据集上,命名实体识别模块的结果如下表所示。基于字的模型比基于词的模型取得了更好的效果:
| P | R | F1 | |
|---|---|---|---|
| LTP | 91.98% | 93.38% | 92.68% |
| HUST-NLP | 94.19% | 94.73% | 94.46% |
词性标注
词性标注(Part-of-speech Tagging, POS)是对连续的词语序列根据上下文内容进行词性的标注(如动词、名词、形容词等),它对更好地理解自然语言文本、对多义词进行消除歧义具有重要作用。在中文领域,常用的词性标注算法主要包括基于词(需要预先进行分词)和基于字两种。目前,在人民日报数据集上,HUST-NLP的词性标注模块的结果如下表所示:
| ACC | |
|---|---|
| LTP | 98.85% |
| HUST-NLP | 98.52% |
句法和语义依存分析
由于句法依存分析和语义依存分析在问题结构上存在相似处,因此,在HUST-NLP中,使用了类似的解决方案。具体来说,我们分别使用了biaffine parser和universal dependency的方法,并在人民日报的测试集上取得了如下的结果。这里,LAS和UAS分别指的是有标签和无标签依存正确率,前者统计的是支配词和对应依存关系同时正确的情形,后者则只需要支配词标记正确即可。
|
句法依存分析 |
LAS |
UAS |
Label_ACC |
|
Biaffine Parser |
81.44 |
84.46 |
87.37 |
|
Universal Dependency |
84.64 |
86.78 |
89.81 |
|
语义依存分析 |
LAS |
UAS |
Label_ACC |
|
Biaffine Parser |
64.93 |
82.28 |
71.67 |
|
Universal Dependency |
65.34 |
82.64 |
71.74 |
平台接口文档
平台各个模块的HTTP接口调用方法。
请求说明
HTTP方法:GET 请求URL: http://39.98.116.40:10001 Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | Application/json |
Header
请求参数:
| 参数名称 | 类型 | 详细说明 |
|---|---|---|
| Task | String | 任务类型 |
| Sent | String | 待分析文本,长度不超过300个字 |
请求参数
示例:http://39.98.116.40:10001/?task=segment&sent=我跟小明去北京玩
平台模块支持选项
基础工具:segment(分词)、postag(词性标注)、recognize(命名实体识别)、syntactic_parser(句法依存解析)、semantic_parser(语义依存解析) 词组提取:coordinate_phrase(并列词组), sepc_phrase(状语词组) 句子解析:sentence_class(句子类型), question_class(问句类型), no_mean_class, zwb(主谓宾) 语义槽:slot,全部功能:infer 请求参数:| 参数名称 | 默认值 | 类型 | 必需 | 详细说明 |
|---|---|---|---|---|
| Task | [任务名称] | String | 是 | 任务类型 |
| Sent | 空缺 | String | 是 | 待分析文本 |
请求参数
返回参数:
| 参数名称 | 类型 | 必需 | 详细说明 |
|---|---|---|---|
| [任务名] | String | 是 | 任务结果 |
返回参数
具体任务API调用表
|
任务 |
请求参数 |
返回参数 |
|||
|
参数名称 |
默认值 |
参数名称 |
类型 |
详细说明 |
|
|
分词 |
task |
segment |
seg |
string |
分词结果 |
|
sent |
空缺 |
||||
|
词性标注 |
task |
postag |
pos |
string |
词性标注结果 |
|
sent |
空缺 |
||||
|
命名实体识别 |
task |
recognize |
ner |
string |
命名实体识别结果 |
|
sent |
空缺 |
||||
|
句法依存解析 |
task |
syntactic_parser |
syn |
string |
句法依存解析结果 |
|
sent |
空缺 |
||||
|
语义依存解析 |
task |
semantic_parser |
syn |
string |
语义依存解析结果 |
|
sent |
空缺 |
||||
|
并列词组提取 |
task |
coordinate_phrase |
coordinate_phrase |
string |
并列词组提取结果 |
|
sent |
空缺 |
||||
|
状语词组提取 |
task |
spec_phrase |
spec_phrase |
string |
状语词组提取结果 |
|
sent |
空缺 |
||||
|
句子类别 |
task |
sentence_class |
sentence_class |
string |
句子类别结果 |
|
sent |
空缺 |
||||
|
问句类别 |
task |
question_class |
question_class |
string |
问句类别结果 |
|
sent |
空缺 |
||||
|
否定类别 |
task |
no_mean_class |
no_mean_class |
string |
否定类别结果 |
|
sent |
空缺 |
||||
|
主谓宾识别 |
task |
zwb |
zwb |
string |
主谓宾识别结果 |
|
sent |
空缺 |
||||
|
全部基础任务 |
task |
Infer |
all_res |
string |
全部基础任务结果 |
|
sent |
空缺 |
||||
|
语义槽 |
task |
slot |
slot |
string |
语义槽结果 |
|
sent |
空缺 |
||||
示例1: 请求:sent = 我跟小明去北京玩 API调用:http://39.98.116.40:10001/?task=segment&sent=我跟小明去北京玩 返回:{"result": {"seg": ["我", "跟", "小明", "去", "北京", "玩"]}} 示例2: 请求:sent = 哪里有我想要的书 API调用:http://39.98.116.40:10001/?task=infer&sent=哪里有我想要的书 返回:{"result": {"all_res": {"seg": ["哪里", "有", "我", "想", "要", "的", "书"], "pos": ["r", "v", "r", "v", "v", "u", "n"], "ner": {}, "syn_parser": ["2-ADV", "0-HED", "4-SBV", "6-DE", "6-DE", "7-ATT", "2-VOB"], "sem_parser": ["2-Loc", "0-Root", "4-Agt", "7-dDesc", "4-mMod", "4-mAux", "2-Clas"], "phrase_ana": {"coordinate": [], "spec": []}, "sent_ana": {"sent_class": "特指问句", "question_class": {"question_word": "哪里", "question_class": "问地点"}, "no_mean_class": "肯定", "zwb": {"状语": ["哪里"], "谓语": ["有"], "宾语": ["我想要的书"]}}}}}
基本API调用示例python代码
import requests
class NlpTool():
def __init__(self, sim_type='tfidf_consine'):
self.url = "http://192.168.1.25:18881"
self.headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/37.0.2062.120 Chrome/37.0.2062.1 20 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9'}
def analysis(self, task, sent):
payload = {'task': task, 'sent': sent}
r = requests.get(self.url, params=payload)
# print(r.text)
return r.text
if __name__ == '__main__':
nlpTool = NlpTool()
sent = '苹果公司发布新手机,其中这款是本公司本年度的第一款5G手机'
# 分词
res = nlpTool.analysis('segment', sent)
print(res)
# 词性标注
res = nlpTool.analysis('postag', sent)
print(res)
# 命名实体
res = nlpTool.analysis('recognize', sent)
print(res)
# 句法依存树
res = nlpTool.analysis('syntactic_parser', sent)
print(res)
# 语义依存树
res = nlpTool.analysis('semantic_parser', sent)
print(res)
# 并列词组
res = nlpTool.analysis('coordinate_phrase', sent)
print(res)
# 状语词组
res = nlpTool.analysis('spec_phrase', sent)
print(res)
# 句子类别(语法上)
res = nlpTool.analysis('sentence_class', sent)
print(res)
# 问句类别
res = nlpTool.analysis('question_class', sent)
print(res)
# 否定类别
res = nlpTool.analysis('no_mean_class', sent)
print(res)
# 主谓宾分析
res = nlpTool.analysis('zwb', sent)
print(res)
res = nlpTool.analysis('slot', '明天洛杉矶会不会下雪啊?')
print(res)
# 以上全部功能
res = nlpTool.analysis('infer', sent)
print(res)